
NGINX Logging 사용하여 애플리케이션 성능 모니터링하기
NGINX Plus의 실시간 모니터링 대시보드 및 API는 시스템의 부하 및 성능을 분석하는 데 사용할 수 있는 많은 시스템 지표를 추적합니다. 요청 수준 정보가 필요한 경우 NGINX 및 NGINX Plus의 NGINX Logging 은 매우 유연합니다. 로그 항목에 변수 형식으로 포함될 수 있는 많은 데이터 포인트 중에서 선택하여 Logging할 데이터를 구성할 수 있습니다. 또한 애플리케이션의 여러 부분에 대해 사용자 정의 로그 형식을 정의할 수도 있습니다.
NGINX Access Logging의 유연성을 활용하는 한 가지 흥미로운 사용 사례는 애플리케이션 성능 모니터링(APM)입니다. 확실히 선택할 수 있는 많은 APM 도구가 있고 NGINX가 이를 완전히 대체하지는 못하지만 타이밍 값을 코드에 추가하고 이를 NGINX에 포함하기 위한 응답 헤더로 전달하여 애플리케이션의 성능에 대한 자세한 가시성을 얻는 것은 간단합니다.
이 포스트에서는 분석을 위해 NGINX 또는 NGINX Plus에서 Splunk로 타이밍 데이터를 공급하는 방법을 설명하지만 Splunk는 단지 예일 뿐입니다. 좋은 NGINX Logging 분석 도구는 유사한 통찰력을 제공할 수 있습니다.
목차
1. NGINX 기본 제공 타이밍 변수 사용
2. 애플리케이션 정의 타이밍 값 사용
3. 결론
1. NGINX 기본 제공 타이밍 변수 사용
NGINX Logging 항목에 포함할 수 있는 여러 내장 타이밍 변수를 제공합니다. 모두 밀리초(ms) 단위의 분해능으로 초 단위로 측정됩니다.
- $request_time – NGINX가 클라이언트에서 첫 번째 바이트를 읽을 때 시작하여 NGINX가 응답(response) 본문의 마지막 바이트를 보낼 때 끝나는 전체 요청 시간
- $upstream_connect_time – 업스트림 서버와의 연결 설정에 소요된 시간
- $upstream_header_time – 업스트림 서버에 대한 연결 설정과 응답 헤더의 첫 번째 바이트 수신 사이의 시간
- $upstream_response_time – 업스트림 서버에 대한 연결 설정과 응답 본문의 마지막 바이트 수신 사이의 시간
다음은 다른 유용한 정보와 함께 이러한 4개의 NGINX 타이밍 변수를 포함하는 apm이라는 샘플 로그 형식입니다.
log_format apm '"$time_local" client=$remote_addr '
'method=$request_method request="$request" '
'request_length=$request_length '
'status=$status bytes_sent=$bytes_sent '
'body_bytes_sent=$body_bytes_sent '
'referer=$http_referer '
'user_agent="$http_user_agent" '
'upstream_addr=$upstream_addr '
'upstream_status=$upstream_status '
'request_time=$request_time '
'upstream_response_time=$upstream_response_time '
'upstream_connect_time=$upstream_connect_time '
'upstream_header_time=$upstream_header_time';예를 들어, 세 개의 PHP 페이지(apmtest.php, apmtest2.php 및 apmtest3.php)가 있는 애플리케이션에서 느린 응답 시간에 대한 불만을 받고 있다고 가정해 보겠습니다. 각 페이지는 데이터베이스 조회를 수행하고 일부 데이터를 분석한 다음 데이터베이스에 기록합니다. 속도 저하의 원인을 확인하기 위해 애플리케이션에 대한 부하를 생성하고 NGINX Logging – 액세스 로그(access log) 데이터를 분석합니다. 이 예에서는 NGINX가 syslog를 사용하여 액세스 로그(access log) 항목을 Splunk로 보냅니다.
다음 Splunk 명령을 사용하여 각 PHP 페이지에 대한 총 요청 시간($request_time 변수에 해당)을 표시합니다.
* | timechart avg(request_time) by request그리고 다음과 같은 결과를 얻습니다(x축에는 요청이 표시되고 y축에는 응답 시간(초)이 표시됨).

여기에서 우리는 apmtest2.php 및 apmtest3.php 의 각 실행에 대한 총 요청 시간이 상대적으로 일정하지만 apmtest.php 의 경우 큰 변동이 있음을 알 수 있습니다. 해당 페이지를 자세히 살펴보기 위해 이 Splunk 명령을 사용하여 해당 페이지에 대한 업스트림 응답 시간(response time)과 업스트림 연결 시간만 표시합니다.
* | regex request="(^.+/apmtest.php.+$)" | timechart avg(upstream_response_time) avg(upstream_connect_time)다음 결과

이는 업스트림 연결 시간이 무시할 수 있음을 보여주므로 크고 가변적인 총 응답 시간(response time)의 원인으로 업스트림 응답 시간에 집중할 수 있습니다.
2. 애플리케이션 정의 타이밍 값 사용
드릴다운하기 위해 애플리케이션 자체에서 타이밍을 캡처하고 이를 응답 헤더로 포함합니다. 그러면 NGINX가 액세스 로그(access log)에서 캡처합니다. 얼마나 세분화할 것인지는 당신에게 달렸습니다.
예제를 계속 진행하려면 표시된 내부 작업의 처리 시간을 기록하는 다음 응답 헤더를 애플리케이션이 반환하도록 합니다.
- db_read_time – 데이터베이스 조회
- db_write_time – 데이터베이스 쓰기
- analysis_time – 데이터 분석
- other_time – 다른 모든 유형의 처리
NGINX는 헤더 이름 앞에 $upstream_http_ 문자열을 추가하여 이름을 지정하는 해당 변수를 생성하여 응답 헤더에서 타이밍 값을 캡처합니다(예: $upstream_http_db_read_time은 db_read_time에 해당). 그런 다음 표준 NGINX 변수와 마찬가지로 로그 항목에 변수를 포함할 수 있습니다.
다음은 애플리케이션 헤더 값을 포함하도록 확장된 이전 샘플 로그 형식입니다.
log_format apm 'timestamp="$time_local" client=$remote_addr '
'request="$request" request_length=$request_length '
'bytes_sent=$bytes_sent '
'body_bytes_sent=$body_bytes_sent '
'referer=$http_referer '
'user_agent="$http_user_agent" '
'upstream_addr=$upstream_addr '
'upstream_status=$upstream_status '
'request_time=$request_time '
'upstream_response_time=$upstream_response_time '
'upstream_connect_time=$upstream_connect_time '
'upstream_header_time=$upstream_header_time '
'app_db_read_time=$upstream_http_db_read_time '
'app_db_write_time=$upstream_http_db_write_time '
'app_analysis_time=$upstream_http_analysis_time '
'app_other_time=$upstream_http_other_time ';이제 테스트를 다시 실행합니다. 이번에는 apmtest.php에 대해서만 실행합니다. 다음 Splunk 명령을 실행하여 4개의 애플리케이션 헤더 값을 플로팅합니다.
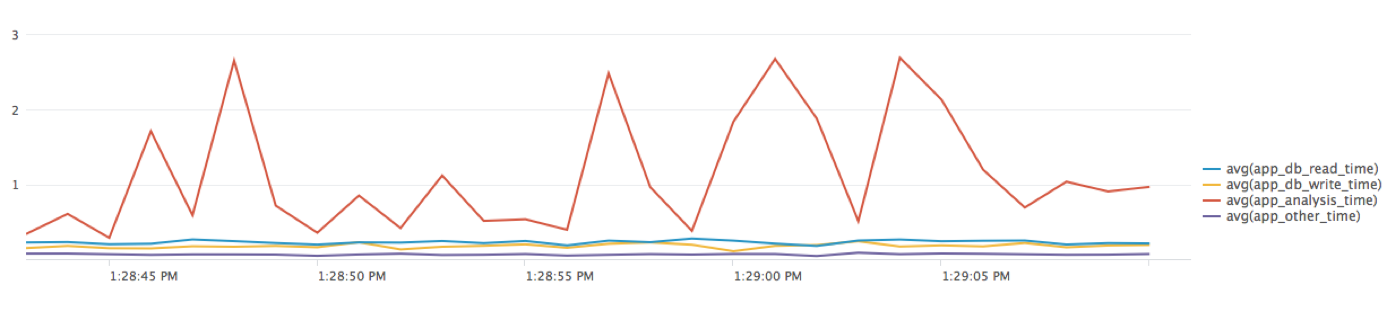
* | timechart avg(app_db_read_time), avg(app_db_write_time), avg(app_analysis_time), avg(app_other_time)그리고 다음과 같은 결과를 얻습니다.

그래프는 데이터 분석이 처리 시간의 가장 큰 부분과 총 응답 시간(response time)의 변동을 설명한다는 것을 보여줍니다. 추가로 드릴다운하기 위해 코드에 타이밍을 추가할 수 있습니다. 또한 특정 유형의 요청으로 인해 응답 시간이 길어지는지 확인하기 위해 NGINX Logging 세부 정보를 살펴볼 수도 있습니다.
3. NGINX Logging 결론
애플리케이션의 성능 문제를 조사하는 데 도움이 되는 정교한 APM 도구가 많이 있지만 비용이 많이 들고 복잡한 경우가 많습니다. 구성 가능한 NGINX Logging 기능과 로그 분석 도구를 사용하여 여기에서 설명하는 것과 같은 간단하고 쉬운 솔루션이 있고 매우 쉽고 비용이 효율적일 수 있습니다. 일회성 문제 해결에 이 접근 방식을 사용하거나 항상 NGINX 액세스 로그(access log)에 애플리케이션 수준 타이밍을 포함하여 문제에 대해 경고할 수 있습니다.
NGINX Plus를 사용해 보시려면 지금 무료 30일 평가판을 시작하거나 당사에 연락하여 사용 사례에 대해 문의하십시오.
사용 사례에 대해 최신 소식을 빠르게 전달받고 싶으시면 아래 뉴스레터를 구독하세요.



{kind=link}
{kind=link}
댓글을 달려면 로그인해야 합니다.